有時候從網路上爬取到的資料型式並不是我們想要的。
ex: "新聞發布於:2020年7月1日 14點20分"。我們只想要後面的時間,並不想要前面的文字。
這時當然可以用最簡單的 .split('新聞發布於:')[1],但當今天前面的文字不一樣時,這個方式就不管用。
ex: 要從 "賴清德" & "賴+sexy6969" 兩個帳號中去判斷哪一個是色情帳號時,就必須使用到正則表達式!
定義字串的樣式
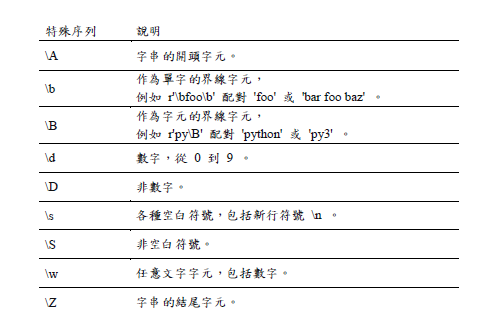

re.search()使用最為頻繁、且最容易使用
用法:re.search( pattern, string )
pattern: 資料型式
string: 要比對的文字
範例1 - 只保留日期:
import re
text1 = '今天的日期是:2020-07-01 14:02:48'
time = re.search(r'\d+-\d+-\d+ \d+:\d+:\d+', text1).group(0)
print(time)
2020-07-01 14:02:48
範例2 - 抓取中間文字:
text2 = '編輯 - 衛斯理 小編'
author = re.search('編輯 - (.*?) ', text2).group(1)
print(author)
author = re.search('編輯 - (\w+)', text2).group(1)
print(author)
衛斯理
衛斯理
範例3 - 判斷色情帳號:
text1 = '賴清德'
if re.search('賴([a-z|0-9])',text1):
print('色情line帳號')
else:
print('正常帳號')
正常帳號
text2 = '賴sexy6969'
if re.search('賴([a-z|0-9])',text2):
print('色情line帳號')
else:
print('正常帳號')
色情line帳號
re.match()從頭開始比對文字
與re.search()的最大差別在於它是檢測文字是否在開頭位置。
用法:re.match( pattern, string )
import re
text1 = '賴清德選上副總統!'
name = re.match(r'賴清德', text1).group(0)
print(name)
賴清德
re.findall()找尋文字中所有匹配的文字
import re
text1 = '編輯 - 衛斯理 小編、編輯 - Christy 小編、編輯 - 阿龍 小編'
author = re.findall('編輯 - (.*?) ', text1)
print(author)
['衛斯理', 'Christy', '阿龍']
 wesley41616
wesley41616
